
Email Emily
How can we help?
Whether you're looking for expert ITSM consulting, cutting-edge technology solutions, award-winning training courses, or hands-on IT support, explore our website and use the search box to easily find the resources, insights, and services you need.
Incident Management
The leading IT Analysts agree that around 80% of all Incidents being reported to the IT Service Desk are caused by Change!
An incident is an unplanned interruption to an IT service, or a reduction in the quality of an IT service. Failure of a configuration item that has not yet impacted service is also an incident.
The purpose of Incident Management is to restore normal service as quickly as possible, to minimise the adverse impact on business operations, and to ensure the best possible levels of service quality and availability are maintained. ‘Normal Service Operation’ is defined as an operational state where services and CIs are performing within their agreed service and operational levels.
Incident Management is highly visible to the business, and it is therefore easier to demonstrate its value than most areas in Service Operation. For this reason, Incident Management is often one of the first processes to be implemented in service management projects. The added benefit of doing this is that Incident Management can be used to highlight other areas that need attention – thereby providing a justification for expenditure on implementing other processes.
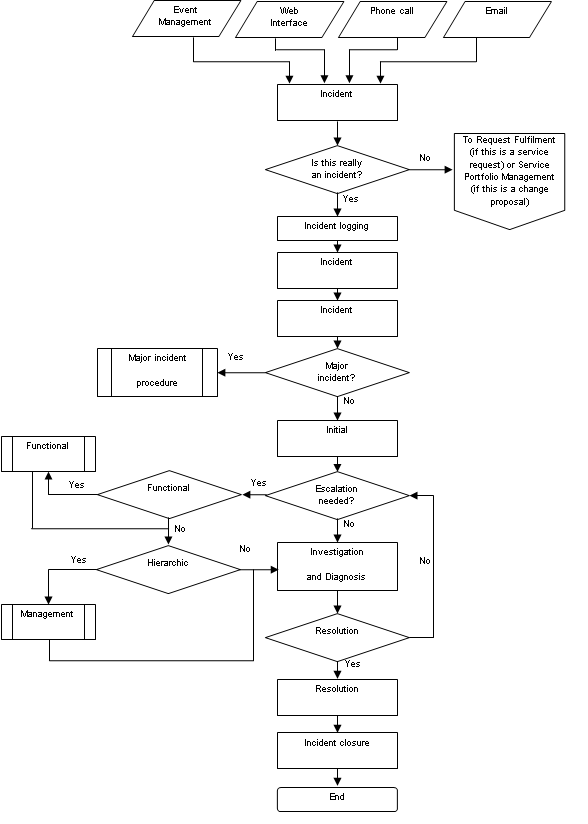
Incidents are mostly detected by users who would then contact the Service Desk, however proactive Incident Management could be detected by Event Management. Incidents are categorized to identify who should work on them and for trend analysis, and they are prioritized according to urgency and business impact.
Incidents should be tracked throughout their lifecycle to support proper handling and reporting on the status of incidents. Within the Incident Management system, status codes may be linked to incidents to indicate where they are in relation to the lifecycle. Examples of these might include:
- Open An incident has been recognized but not yet assigned to a support resource for resolution
- In progress The incident is in the process of being investigated and resolved
- Resolved A resolution has been put in place for the incident but normal state Service Operation has not yet been validated by the business or end user
- Closed The user or business has agreed that the incident has been resolved and that normal state operations have been restored
Customers must be kept informed of the status of their incident at all times.
If an incident cannot be resolved quickly, it may be escalated. Functional escalation passes the incident to a technical support team (2nd line support) with appropriate skills; hierarchical escalation engages appropriate levels of management.
Always try to have different people responsible for Incident Management and Problem Management – these are different skills. Incident Management all about getting the customer back to work as quickly as possible, whereas Problem Management is about investigating the root cause of Incidents, which is a longer process.
Incident Management Activities:
Case studies
Rapid results: a new ITSM Platform in 54 days
When Ivanti announced the end of life for Cherwell, SCS JV faced an urgent challenge. More than a service-management tool, Cherwell provided crucial identity and access management for the project, controlling who could see sensitive project data across 22 live construction sites. With more than 2,100 project staff and between...
Growth powered by Pink Elephant’s SIAM IT Service Desk
Corplex (formerly DS Smith Plastics, Extruded Products) is a leading manufacturer of innovative reusable packaging. With a history spanning 50 years, Corplex rebranded in 2020 after being acquired by Olympus Partners. The company is dedicated to sustainability and excellence, establishing itself as a trusted name in the Reusable Transport Packaging...

Bespoke Customer Service training programme for GTT
Pink Elephant EMEA builds on the success of a GTT’s customer service offering with a bespoke virtual training programme. Find out more below about the objectives, challenges, and successes of delivering a training programme to 250+ GTT employees, in three countries, across three time zones. Find Out More about Customer...